
All translations, whether approved or not and whether obtained with MT or from a human, are remembered in a project's memory.
The system keeps track of quality levels per each translation. It knows which translations are human edited and which were done by machine.
We already saw that the Beebox splits your text content into smaller segments, typically the size of a sentence or paragraph. If a specific sentence was translated into Chinese earlier and the exact same sentence shows up in another file, Beebox can immediately pretranslate the sentence. Think of a text such as “Click here”. It may show up hundreds of times in a web site, but Beebox will send it to an MT or a human translator just once!
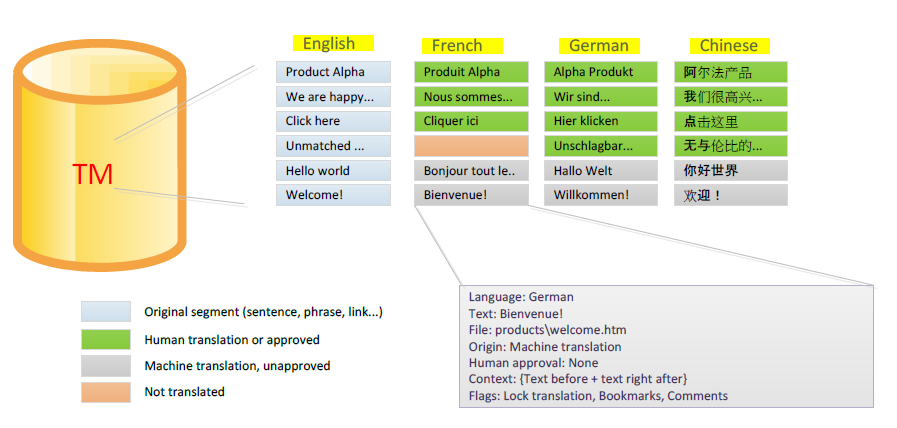
When a new or updated file is added to Beebox, it will look up each « segment » in the translation memory. Even if the file is completely new, there is a very high likelihood that some translations from other files can be reused. This helps to reduce overall translation costs.
A Beebox project can be configured for different leveraging modes:
-
Leverage translations of identical texts from wherever they come from, like in the “Click here” example above. This is the default mode and fine with most content.
-
Leverage translations only if the source text is identical as well as the context, i.e. the segment above and below the text. Sometimes translations are done differently depending on the context. This mode produces potentially higher quality, but also more segments to translate.