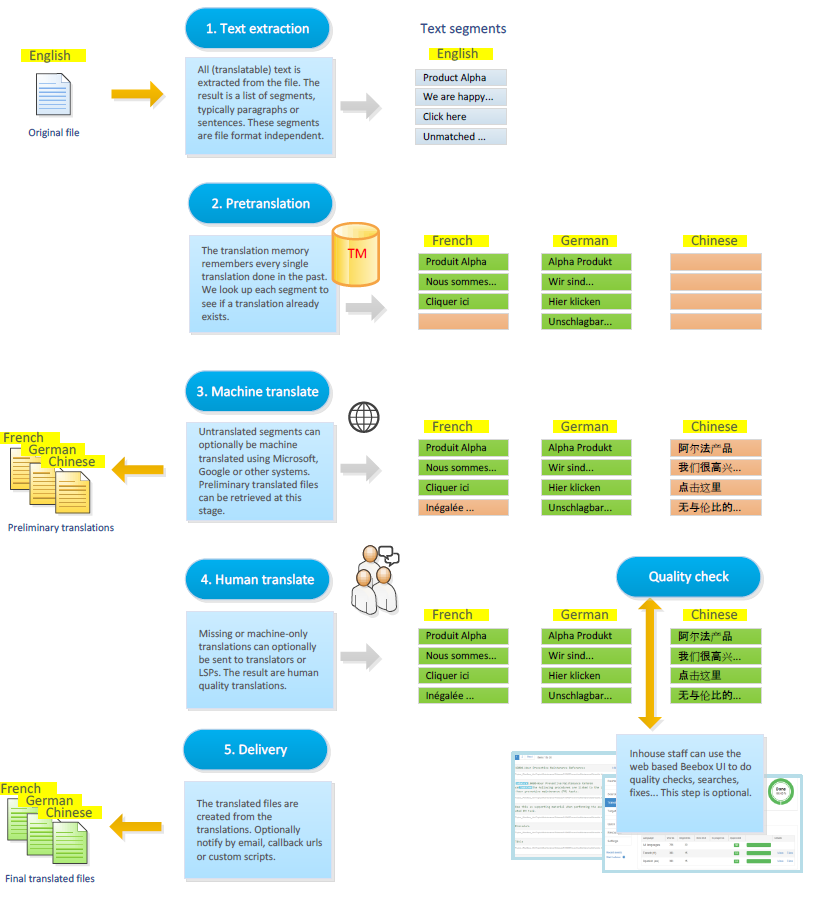
With each file or set of files you copy/send to the Beebox, a number of steps execute to get your content translated:
This process applies to regular projects. Pass-through projects use a simplified process.
Step 1 - Extract source content
Only applies to new or updated source files in the "in" directory. Files that were already processed in the past are skipped (by default).
-
Text extraction: Translatable text is extracted from the source files. The "text extraction rules" are customizable.
-
Segmentation: Text is split into smaller units, so called "segments". These typically are of the size of a sentence.
Segmentation can be switched off altogether, this makes sense when inputting files that support aligned content in multiple languages: XLIFF, XML, JSON or EXCEL.
Step 2 - Alignment of translated files (OPTIONAL)
Only if enabled and a translated file exists in the "out" directory.
-
Find translated file: If alignment is enabled for all or the specific file, the Beebox looks for the translated file in the "out" directory. The file must have the exact same name as the source file.
-
Extract target content: Same operations as described in step 1 above but for the translated file.
-
Align source and target: Uses alignment technology to pretranslate the source content from the target files. The algorithm approves aligned translations only if the confidence level is above a threshold. Otherwise, the translation is not approved (and requires human approval). Alignment is trained from existing project/translation memory contents.
Step 3 - Pretranslate using memories
Only applies to segments that were not translated in previous steps.
-
Reuse translations: Attempts to find identical segments already translated in the past.
-
From project files: Reuses translations done for other source files in the project ("project memory").
-
From memories: Reuses translations from translation memories uploaded to the project.
Step 4 - Machine translation (OPTIONAL)
Only applies to segments that were not translated in previous steps
-
Machine translation: Optionally uses Google, Microsoft or another system to translate segments (except the pretranslated ones).
-
Pseudo translation: Optionally simulates a translation by converting source text into uppercase or applying other transformations. This is often used by software localization teams for testing.
-
Output preliminary target files: Optionally creates the translated target files and saves to disk. This is useful if you need a preliminary translation while waiting for the final, human edited versions.
Step 5 - Human translation (OPTIONAL)
By default, applies to segments that are not yet translated or not yet approved.
-
Create translation jobs: Picks all untranslated or machine-only translated segments and creates a translation job.
-
Exchange jobs with translation teams or a TMS (translation management system):
-
Use Wordbee Translator: Directly send jobs to a Wordbee Translator platform, using a secure web link.
-
Use manual import/export: Login to Beebox to export each job (XLIFF file) and import back translated XLIFFs.
-
Use hotfolders: Automatic transfer of XLIFF jobs to a hotfolder. Automatic reception of translated files from hotfolder. Use to integrate with 3rd party translation management systems.
-
-
Approval and QA:
-
Automatic or manual approval of completed jobs ("commit job"). The translations are now used to translate source files.
-
Step 6 - Create final translated files
Applies to files of which all translations exist and are approved.
-
Create translated files: Once all translations are approved, Beebox creates translated files in the project "out" directory. This can be configured to be an automatic or a manual step.
-
The process is complete.
The key steps are depicted below: