
This page provides additional insights on two sensible topics: pre-translation and segmentation processes.
Thresholds for pre-translation together with segmentation rules can be the reason for discrepancies in the leveraging rates you expect or in the segment length limits that must be respected for each cell/node in the file.
For example:
-
Differences in the segmentation between your working materials and of the resources attached to the project can result in lower pre-translation rates, increasing the cost of the new translations.
-
Multilingual files or resources enabled for re-use can introduce in your translated document pre-translations of different types that may go beyond the char limits enforced by the document format profiles in the settings, introducing potential friction points in the localization process.
Luckily, Wordbee has a broad toolset that can help you sort out these situations in a convenient way, making clear to each user what is required for them each step of the way.
Find below some common scenarios and the way to solve them in the system.
How to handle character limits for one large Excel cell that contains multiple sentences and that is segmented in the online Editor?
Single segments don't have a character limit each but the cell as a whole does have one. To have a clear vision of how the text will be imported to the online editor, the user needs to take a look at the text segmentation rules for this particular file format:
The same logic applies to the following file formats: CSV, XML or JSON.
What are your document format settings for Excel when it comes to taking into account the SRX rules?
If you read out the values from the excel file and everything is correctly set, then Wordbee will import each segment from this big cell as one stand-alone segment. The text of the cell will be divided in different children segments, numbered as it follows: 1, 1.1, 1. 2 etc.. The maximum length value is assigned to the first segment and all related children segments will be dependent on it.
Have the character limitations been read from the Excel during import and how did you configure it exactly? Or did you manually set the limitations in the QA profile?
When running a QA check, all the children segments belonging to the same cell (1, 1.1, 1.2 etc.) will be compared against the total value of the cell assigned to segment 1. If the result it's above the limit, the user gets a QA warning/error.
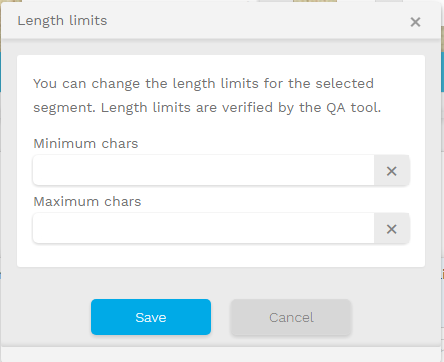
The new Editor has the possibility to set the length limit for each segment
You just need to click on the 
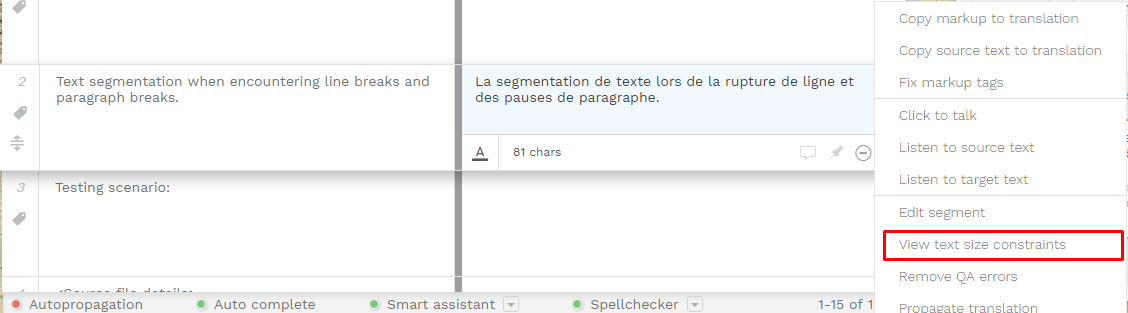
The following popup window will open, allowing you to set up the limit for this particular segment (by default there are no length restrictions)
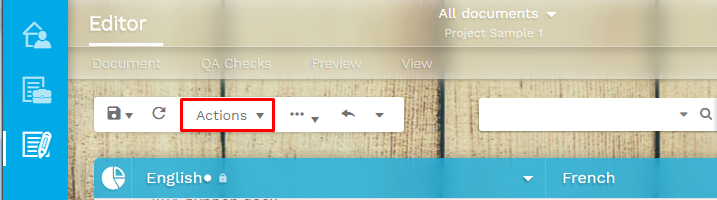
You can also set the length for a group of segments on one go. You just need to run a filter to have them all displayed and select the set text length constraint function, from the actions menu.
Manager and administrators can even prevent users from typing extra characters when the text length has been reached ! This global setting is to be configured in the Editgor preferences.
What if character limitation has been enforced globally in the system and pre-translations available for each segment exceed the max. value?
In these cases, if pre-translations from linguistic resources (translation memories, terminology databases) exceed the pre-set number of characters defined in the text extraction parser, pre-translations will have priority, regardless of the text constraints limitations. This is also applicable when retrieving past versions of the translation from the Timeline or even when translating using batch actions such as "Translate from Memories" or copy source to target".
Translators will need to rely on the Quality Assurance feature to make any required changes to target texts prior to marking the job as completed. We recommend to make the QA function mandatory to ensure translators run a QA prior to completing their job.
Also, when character limitations have been enforced globaly in the platform and users want to automaticaly insert text from the Translation Finder, the system will prevent them to exceed the limit defined.
Examples of such actions could be:
-
Automatically copy top translation memory hit to editor
-
Copy source text to editor if no translation memory hit found
-
Automatically translate terms from translation memory or terminology database hits
In all such cases, the text will be cropped down to the limit of each segment. This means, segments containing subsegments will need to sum the total of characters defined by the text length constraint.
If the limit is reached, it is possible that these hits won't be fully copied (or not copied at all) to the target segment of your choice.