
Wordbee Translator integrates Optical Character Recognition (OCR) technology that enables you to extract the text contained in images such as PNG, JPG, TIFF, ICO, BMP and many more. The tool returns an HTML file, ready to be edited or translated.
Image to text sample
See the sample image below and how the result is extracted.
|
Uploaded image: 
|
Extracted text: 好一朵美丽的茉莉花
|
Convert image files to text
-
Go to a project and open the document library.
-
Upload or drag & drop your image file:
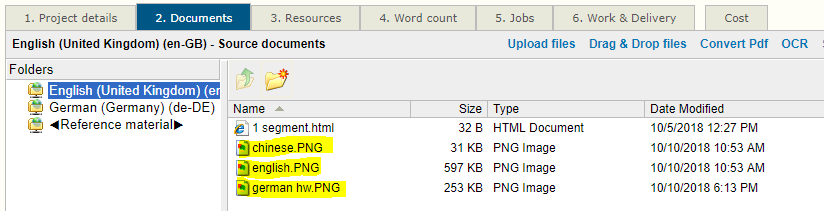
3. Click images to select one or more images. Then click the OCR link above the files. The OCR tool opens:
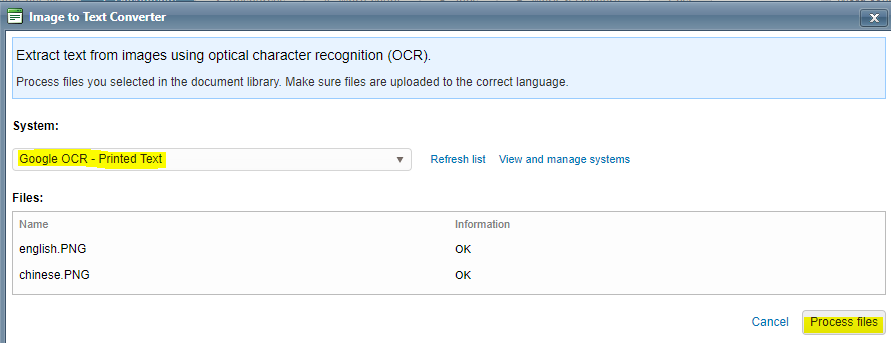
4. Choose one of the OCR systems and hit Process files. The results are saved next to the images:
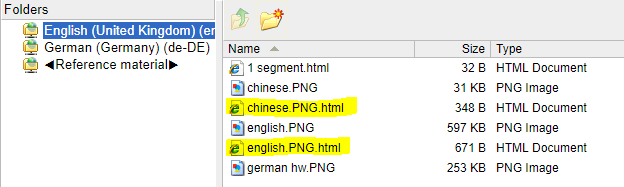
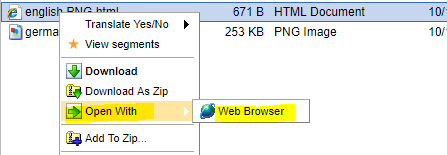
5. To rapidly check if the text was properly recognized, right-click one of the .html files and select the
Open with > Web Browser option:
Handwritten text (English only)

Among the integrated OCR systems, the Microsoft OCR can extract handwritten English text. Here is a sample image and how the text has been extracted.

chapter
Mr. Sherlock Holmes
In the year 1878 I took my degree of Doctor
of medicine of the university of London
and proceeded to Netley to go through
the course precribed for surgeons . Having
completed my studies there . I was duly attached
to the Fifth Northumberland Fusiliers as
Assistant
Surgeon
How to enable the OCR systems
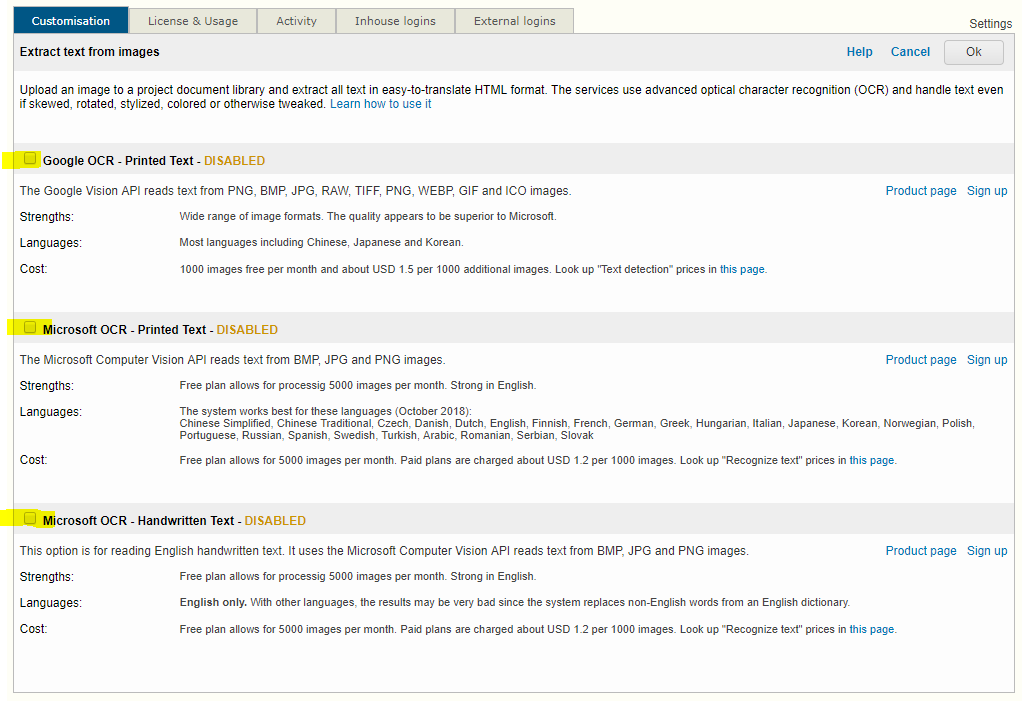
The OCR technology is provided by Google and Microsoft (more systems may be added in the future). You need to obtain credentials from either of those. Both propose free and paid plans. The free plans allow you to convert up to 5000 images per month. Beyond that, you are charged but the cost is reasonable.
-
Go to Settings > Image to Text (OCR) and enable the systems you would like to try.
The sign-up process with Google and Microsoft is not the most intuitive. If you have any questions please .
What about PDF files?
-
If the PDF was created with a word processor and it is not a scan, then you can use the PDF converted tool in the project page.
-
If the PDF contains scanned pages, then you could save the individual pages as image files. This can be done with a screenshot tool.
We may add a direct PDF scan to text feature at a later time.
Related topics
Configuring image files for online translation