
Let's take a look at the inner workings of the Beebox. Skip if you do not want to dig that deep.
The Translation Process
The system may be configured to use any combination of machine translation[1], pseudo translation[2] and human translation. It adapts to your exact requirements. During development you will likely want to use a workflow that employs pseudo- or machine translation and skips any cost incurring human work. In production you will want to add human translation.
Here is a visual explanation of what happens to files placed in the “IN” directory or sent via the API:
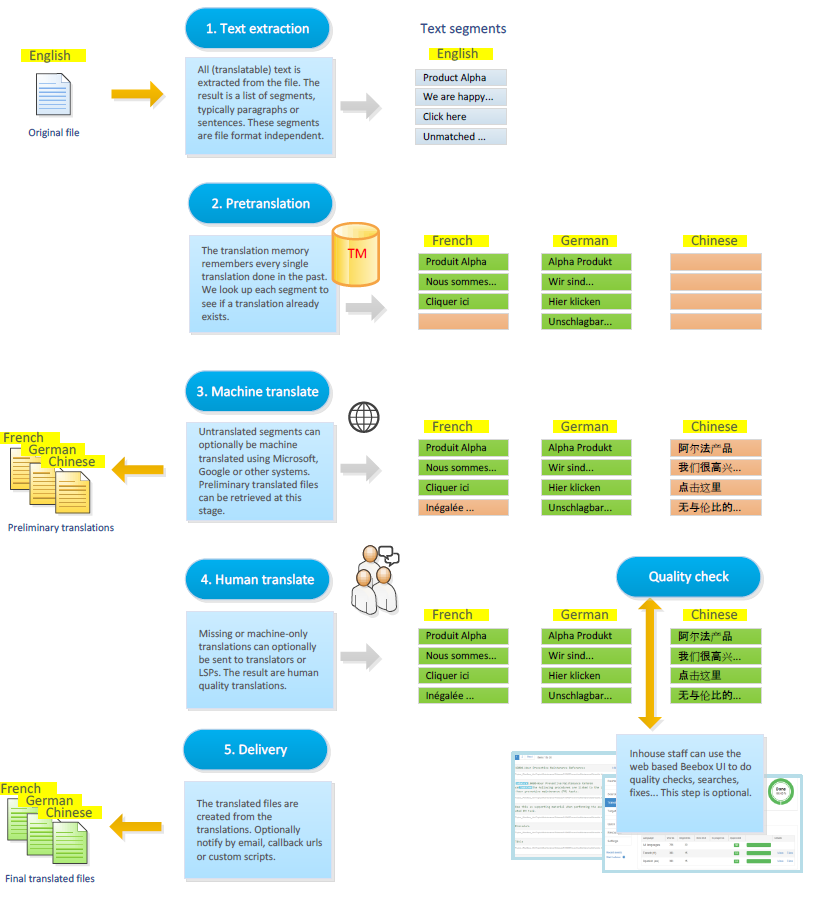
For a more detailed explanation please go here.
What is the purpose of the translation memory?
All translations, whether approved or not and whether obtained with MT or from a human, are remembered in a project's memory.
The system keeps track of quality levels per each translation. It knows which translations are human edited and which were done by machine.
We already saw that the Beebox splits your text content into smaller segments, typically the size of a sentence or paragraph. If a specific sentence was translated into Chinese earlier and the exact same sentence shows up in another file, Beebox can immediately pretranslate the sentence. Think of a text such as “Click here”. It may show up hundreds of times in a web site, but Beebox will send it to an MT or a human translator just once!
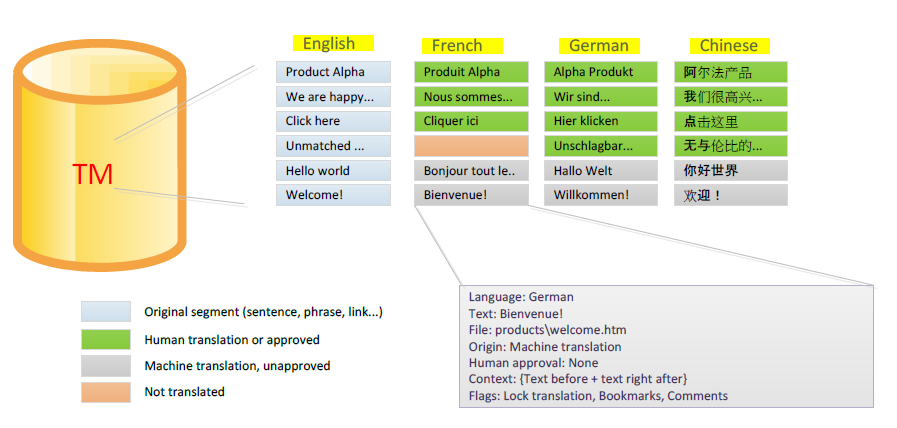
When a new or updated file is added to Beebox, it will look up each « segment » in the translation memory. Even if the file is completely new, there is a very high likelihood that some translations from other files can be reused. This helps to reduce overall translation costs.
A Beebox project can be configured for different leveraging modes:
-
Leverage translations of identical texts from wherever they come from, like in the “Click here” example above. This is the default mode and fine with most content.
-
Leverage translations only if the source text is identical as well as the context, i.e. the segment above and below the text. Sometimes translations are done differently depending on the context. This mode produces potentially higher quality, but also more segments to translate.
What happens if I send a new version of an already translated file?
Beebox will start by extracting the text content and split it into segments. It then attempts to pre-translate all segments from the translation memory. If the new file version did not change, then Beebox will find all translations in the memory. It is then consequently able to fully translate this information and send back the translated file to you. Otherwise, it will pretranslate all unchanged segments and move the added or changed segments to MT or human translation.
For example, if a single word is replaced inside a huge iOS strings-file, only the one string containing the changed word will be sent for MT or Human translation. All the other strings are reused from the translation memory. As you can see Beebox is a safeguard for spending money on translation where this is not necessary.
When Beebox pretranslates a piece of text (segment), there may be multiple choices. To maximize pretranslation quality, the system uses heuristics to choose the best translation:
-
It first attempts to pretranslate a file from the previous file version (if one exists).
-
It gives more weight to approved translations.
-
It gives more weight to pretranslations when the context matches (text before and after).
-
It gives more weight to pretranslations done or post-edited by human translators.
-
It gives less weight to translations with QA (quality assurance) problems
Does Beebox run automatically and unattended?
Yes, Beebox is capable of running automatically with little to no human intervention – like a true black box. However, you can also configure Beebox to wait for confirmation at certain steps in the workflow. Examples are:
-
Confirming work before it is sent to translators (e.g. to check cost).
-
Validating work received from human translators.
In the second example, you would connect to the web interface of your Beebox to filter translations, run checks, manually correct problems, or send the translation back to the translator. In general, it is recommended to automate all steps.
Alignment - Can I send already translated files?
Yes, Beebox incorporates alignment technology as translated versions may be sent with your source files. Beebox splits source and translations into segments and aligns them. In other words, you can send existing translations to Beebox without having to create translation memories in advance (using 3rd party alignment software). It is as simple as that!
The ability to include translated files also serves another purpose. Imagine that a file had been translated in the past. Now, someone edits the translated content (outside Beebox) and changes one or two sentences. The next time you send the source and translated files to Beebox, it will align the files and identify the changes in the translation. The changes go to the human translation team for approval. This use case is specifically interesting with CMS connections where CMS proofreaders may want to edit the translated content and then send the content to Beebox so that its memories are updated.
[1] The Beebox interfaces with major online machine translation systems such as Google and Microsoft.
[2] To simulate translation workflows. « Translates » by converting text to lower or uppercase. Shift letters, etc.