By default, when you or the system creates a job, the job may contain translatable segments coming from any file in the project. This default behavior is just fine in most cases, but not all.
You have two means to separate content across jobs:
-
Have Beebox create a separate job per each file (one job = one file). Simply configure your project for single file jobs. No need to read further.
-
Group files into jobs by their folder or extension. This is what this page is all about.
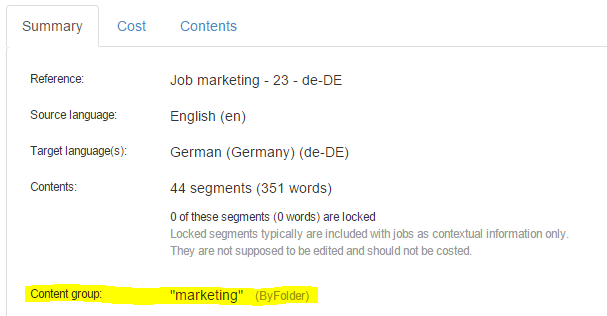
Content:
Configuring content grouping
Go to the project settings page and navigate to the job settings:
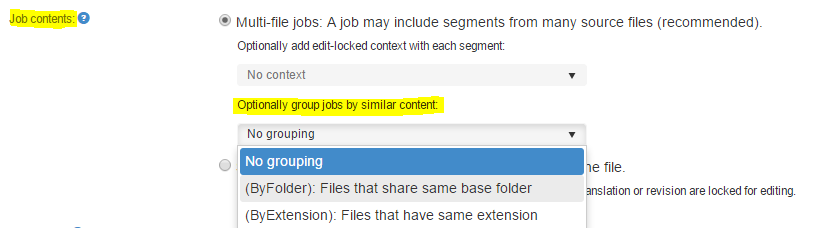
Select a grouping:
-
No grouping: The default. A job can contain any content from any file.
-
Group by folder: Files inside the same base folder are added into the same job.
-
Group by file extension: Files with the same extension (.docx, .html...) will be added into the same job.
-
Group by meta data: Files with the same meta data are added into the same job. Read explanation further down.
Let's assume our project "in" directory contains these files:
in\
file1.docx
file2.docx
marketing\
brochure.docx
sub\
another.html
technical\
documentation.docx
documentation.html
Group content by root folder
Select the ByFolder option in the screen above and save the settings. When you now create jobs, manually or using Autorun, you will get three jobs:
-
A job with segments from "file1.docx" and "file2.docx". The group name is "".
-
A job with segments from "brochure.docx" and "another.html". The group name is "marketing" in both cases.
-
A job with segments from "documentation.docx" and "documentation.html". The group name is "technical".
Group content by file extension
Select the ByExtension option in the screen above and save the settings. You will obtain two jobs:
-
A job with segments from "file1.docx", "file2.docx", "brochure.docx" and "documentation.docx". The group name is "docx" in all cases.
-
A job with segments from "another.html" and "documentation.html". The group name is "html".
Group content by meta data
Select the ByMetaData option in the screen above and fill in the "grouping pattern":
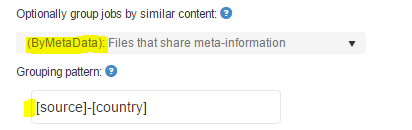
The pattern contains one or more meta information placeholders (the IDs of meta data enclosed with square brackets, case sensitive). Per each file saved to Beebox, the system will replace these placeholders with the file's meta data. For the screenshot above this may produce a group name like "Alpha-France" if the file has meta information "source" with value "Alpha" and meta information "country" with value "France". Finally, the system will group segments into a single job if the segments' files share the same group name.
Where do I get the meta data from? There are two possibilities:
-
Assign meta data to folders. All files you put into a folder will be assigned specific meta data. See Folder level instructions (look for meta data)
-
Assign meta data to each file. See File level instructions (look for meta data)
If you have questions please ask the community or support.
Note: A job has a configurable maximum size limit. With big or many files the system may create multiple jobs per base folder.
Configuring job references
You may now want to include the category with the job reference. Go to the project settings page and edit the job reference format:

The {group} placeholder is replaced by the group name such as the base folder or the file extension. This is what we get from the example further up:

Where can I see the category of my jobs?
The content grouping details are shown in various places:
In the jobs list as shown in the screenshot above.
In the job details page: