
XLIFF allows you to natively define the size of your translation units in any locale. The size limit is defined at segment level, which means that any existing sub-segments rely on the same meta information attached to that segment. This means, if a segment has subsegments (segment 13, 13-1, 13-2, 13-3) they all share the same context or segment properties.
In any case, the information on text length constraints is always passed over to the Editor so you can apply with confidence your QA checks and have the problematic segments highlighted. You will always be able to verify the text length constraints in the main sub-segment, listed without index (segment 13 in the example above). However, if you are working offline you may not have visibility of the limitations applied to subsegments so you will need to process your files twice, with different text extraction profiles:
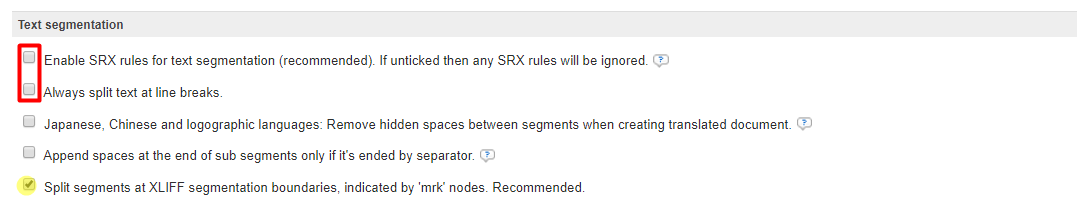
Translators will be able to do their best attempt in the translation to respect the maxwidth for whole the segment.
To verify the information passed as maximum text length check the related article How do I pass over the text length constraints contained in my XLIFF files?