
In Wordbee Translator, a profile may be created and used during automatic word counts in the system for documents within a project. Word Count profiles may be created for each client, specific types of documents, individual products, etc.
To access these settings, go to Settings > Translation Settings > Word Counting. Then click on Add New to create a new configuration in the system.

A default word count profile is also provided and may be modified to meet your specific needs.
In the following sections you learn how to create a word count configuration:
Create a new word count profile
-
Click on Add new.
-
Name the configuration (e.g. to identify a task or a client).
-
Add comments, if necessary.
-
Select the count algorithm:
-
Default - Counts comparable to other translation tools.
-
Microsoft Word compatible.
-
Fuzzy Match Intervals
Fuzzy match intervals define the accuracy of matches between text segments and previous translations in your databases. This is not to be confused with discount percentages, as these items are defined in the pricelist information. Discounts in the pricelist are applied based on the intervals and your fuzzy match intervals should match what has been defined for discounts in the pricelist.
Within the word count profile, you are able to set intervals for fuzzy matches. These matches are displayed in the system analysis information and should correlate with the discount intervals you have defined in the corresponding pricelist.
For example, if you have defined a 90% discount for Interval 2 then any fuzzy matches at this interval will be automatically discounted by the system. Another example might be a discount for in-context matches where the percentage is 100 to 110%.
To set the fuzzy match intervals, click on the increment/decrement buttons or click and choose a percentage value from the drop-down menu for each interval.

In the example below, three intervals have been defined ranging from 80 to 110 percent:

Pre-Translation Options
The Pre-Translation Options are used to define a percentage for pre-translating texts from translation memories. The similarity must be equal to or above the percentage to be pre-translated and appear in the CAT editor. You can also enable pre-translation from project memories, enable machine translation, and configure additional options.
Pre-translation from Memories
Define the percentage of pre-translated texts from resources (translation memories, terminology databases, and project memories) that will appear in the CAT editor.
Setting the percentage too low will result in unreliable pre-translated texts appearing in the CAT editor thus causing the information to be rewritten. It is easier in these instances to perform the translation manually. A lower percentage decreases reliability and the recommended percentage is 100%.

Pre-translation from Project Memories
This option must be enabled if you want the project memory to be used for pre-translation. If it is disabled, then the project memory will only be used for counting repetitions across documents 
Pre-translation by machine (MT)
By default the word count configuration is not set up to machine translate any texts that have not been translated or pre-translated through the above options. In order to use this option, you will need to have a Machine Translation System activated in Wordbee Translator. To learn more, see section underneath Administration.
Once this has been done, you will be able to enable this option and use the system to pre-translate text. First, the text will be pre-translated with the translation memories and project memories (if present). Then the MT will be used to pre-translate any segments that are left empty and could not be pre-translated with the available resources.

Count already translated segments as pre-translations
This option is disabled by default. In some instances documents might be uploaded that already have pre-translated texts. This specific setting can be enabled to extract pre-translated texts and automatically include them as part of the pre-translation count. This is helpful for certain file types such as XLIFF bilingual files and Excel or XML multilingual files where some of the text segments are already translated.
When enabled, the pre-translated texts are extracted from the uploaded file, counted as pre-translated text, and applicable discounts are applied by the system for analysis. It is important to tick this option if you provide discounts for pre-translated text in the document.

Lock pre-translations (make read-only)
If enabled, any pre-translations are noted with a Lock icon and can be viewed, but not modified. This is beneficial at times when the pre-translation is perfect or exact, because no time is wasted on changing an already correct translation. A 100% discount can be instantly applied and it in these instances, changes are not necessary.
Tick the checkbox next to each pre-translation match you want to make read-only. In most instances this will be Perfect (110%) matches and potentially Exact (100%) matches from memories, projects, or previous file versions. You are able to mark fuzzy matches below 100% and machine translation text as read-only as well.

Count pre-translations as "not to translate" (do not cost)
Much like the option above, this setting can be enabled to mark 100% context matched text segments as "not to translate' in the system. When ticked, the information does not appear in the word count analysis and the client does not pay for them. It is another way to ignore these counts in the cost calculation to ensure clients are not charged for already translated perfect match texts.
As with above, you are able to tick the checkbox next to each pre-translation match you want to be not translated. In most instances this will be Perfect (110%) matches and potentially Exact (100%) matches from memories, projects, or previous file versions. You are able to mark fuzzy matches below 100%, machine translation texts, and locked segments as "not to translate" as well.

Substitute dates and numbers
Enabled by default, this option informs the system to replace dates and numbers in a similar memory hit for pre-translation to ensure the corresponding date and numbers in the source text are present in the pre-translation.
These hits are not exact (100%) matches thus requiring the pre-translation threshold for the Pretranslation from memories option to be below 100%. An exmaple might be setting it to 99% to ensure it is as precise as possible. If you do not want this to happen, you can disable (untick) the option and leave the percentage for this Pretranslation from memories option at 100%.

Fix markup during pre-translation
A recommended setting that is enabled by default. When enabled, formatting existing in a memory hit is automatically adjusted. Inline tags are added, renamed, and removed accordingly so they mach the formatting of the translated text.

Repetitions within Project
The Repetitions within Project settings can be used to configure how repetitions are handled during word counting.
-
Enable repetition counting - This option is enabled by default. When enabled, repetitions between project documents and counts are considered as "fuzzy matches" or "repetitions". If the option is enabled to pre-translate segments, then this will be done by the system and will look for repetitions only in fuzzy matches within your memories.
-
Identical or similar repetitions - Enable this option if you want to only count identical repetitions. When enabled, the system will count precise and exact repetitions (100% or 110%) or find similar matches based on the intervals defined in this configuration.
-
Translated or untranslated repetitions - Disabled by default in the settings. When enabled, the system will count hits in other documents when already translated. The system looks for similar/identical repetitions in the actual document and across all other documents in the project. This option ensures that already translated hits in other documents are counted.
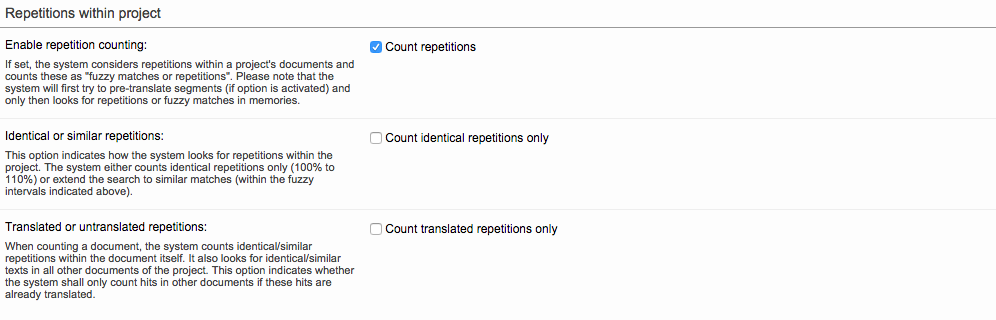
Advanced Settings
The Advanced Settings can be used to generate a smaller or larger word count. For example, if you are a LSP, it might be beneficial to tick all of these options or any that apply. However, if you are a company, unticking them will generate a smaller count to ensure the minimum is paid to the supplier.
These options include counting the following as words:
-
Alphanumeric Sequences
-
Well Delimited Numbers
-
Any Numbers
-
Punctuation Characters
-
Any Symbols
-
Dates as One Word
-
etc...
Save the Configuration
Once you have entered a name, chosen the algorithm, entered fuzzy match intervals, and configured all applicable settings, click on Save in the upper right corner of the screen.
Additional Actions
Additional actions can be performed after the word count profile has been created including modifying the profile, removing it, or creating a new one from it. These actions are available by using the Down Arrow to the right of the profile name or by clicking on Select.

By clicking on the Down Arrow, you are able to see the details of the profile, make changes, create a copy from it, or remove it from the system. Just click on the desired option in the provided drop-down menu.
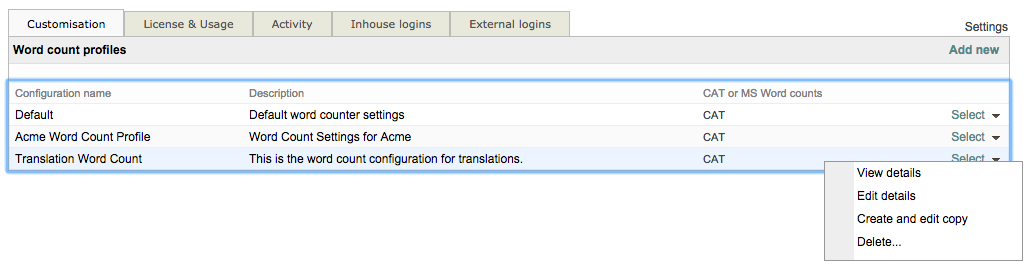
If you click on Select, you will be able to view the details of the configuration and make changes. Use the Back to List option to return to the list of current word count configurations.

Once a Word Count Profile has been created, you can select it for new projects (Standard or CoDyt), configure it as part of the new order form, and assign it to existing projects. For more information about assigning a profile to a project, please see the Assigning Word Count Profiles page.