As documents are translated within a project, these translations are added to the project memory. Every project has a memory that is continuously updated as work is performed on the online CAT editor, until it is completed.
At the end of the workflow, the project memory should be consolidated with a master memory (a translation memory) for use on future projects. If it is not consolidated, then this information will not be available for later pre-translations using an existing master TM. By consolidating you are able to do the following:
-
Use the translation data for new projects.
-
Remove the project from the system without losing this data.
-
Before running a versioning process, if the new version of a file does not need to be translated into all languages first requested.
A master TM can exist for a client, specific domains such as legal, certain types of documents, etc. To learn what a project memory is, please see the What is a Project Memory? page.
When is the consolidation launched?
Usually, the completion of a workflow indicates there is no further work required for that document. We can then consider that these segments are reliable and ready for reuse in other projects. Whether your project contained several files or just one, or if you need to translate into several target languages, it is possible to:
-
Automate the consolidation process is something in the workflow template of your project or
-
Manually run the consolidation of the files.
Learn how to do it in the following sections:
If you do not consolidate project memories with existing translation memories, removing a given project from the system will cause the loss of translations. Additionally, since the memory data is not being merged into a reference database for new requests (aka. consolidation or master memory), unless you are linking existing projects among them, you will not be able to reuse existing translations when launching new projects.
The options below are common to any consolidation strategy you may choose (automatic vs manual)
Copy contents to more than one Translation Memory
Nobody prevents you from sending the contents of a specific project to more than one translation memory. However, the common practice is to centralize all translations done for a given client/domain in a common resource (the Master TM) and make it available in all the projects of the same nature.
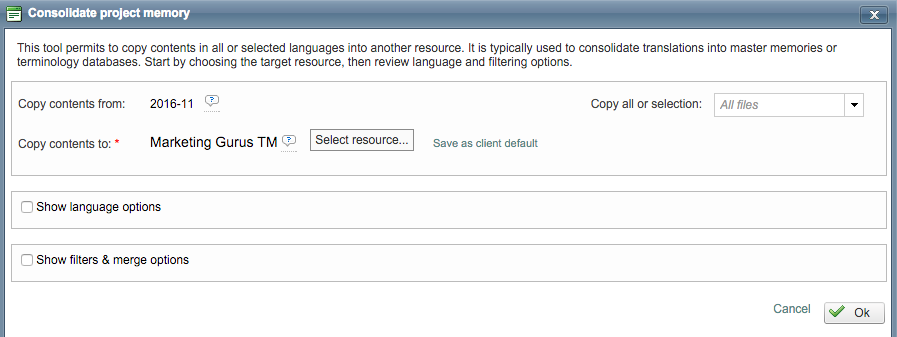
Note the last memory used for consolidation in that project will always be proposed to you if you run the operation more than once.
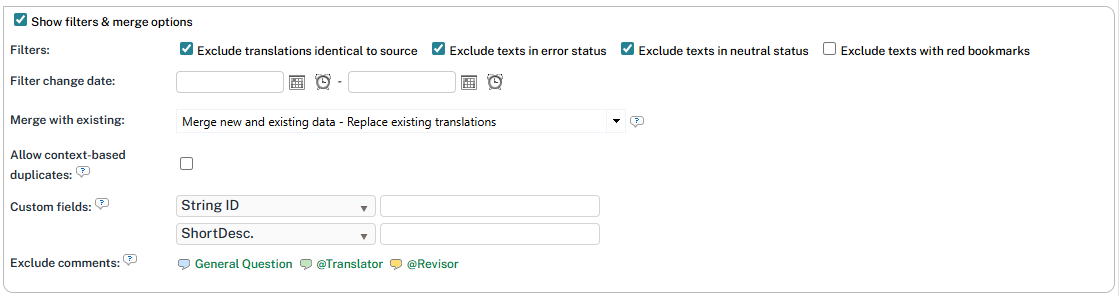
Filters & merge options to process translated segments
Filters
These checkboxes allow using additional options for filtering segments and merge them into the desired memories.
The first two filters (translations identical to source and texts in error status) are checked by default and recommended for any project memory consolidation.
Excluding texts with red bookmarks is optional. This option refers to any segment in the translated document(s) currently marked with a red pin (bookmark).
Excluding texts in neutral status is also optional. Neutral segments are those left in the default grey status, never explicitly confirmed (green) or flagged as problematic (red). When enabled, only positively confirmed segments are consolidated into the master memory. Combine it with the red-status filter to consolidate green segments only.

Consolidation options
Merge into existing segments vs. create new segments
Additional options include entering a filter change date range. If dates are entered here, then only translation changes within that range will be merged. The following merge options are also provided:
-
Merge new and existing data - Replace existing translations (Default) - This will merge the two memories and replace any existing translations. It is the recommended selection.
-
Merge new and existing data - Do not import if translation already exists - This will merge the two memories but not replace existing translations in the master TM.
-
Do not merge but skip doubles - Data will not be merged, but instead added to the TM and all doubles will be skipped.
-
Do not merge and do not look for doubles - All data will be added to the TM, but not merged (doubles will exist).

Handling Context Matches
You can further refine how duplicates are handled using the Allow context-based duplicates option.

When enabled, segments with identical source and target text are imported as new entries if their context metadata differs. This ensures you can leverage 110% matches without causing excessive duplication resulting in large files.
Setting the default at the resource level
Each translation memory has its own default value for Allow context-based duplicates. To configure it, open the resource, go to Search settings, and locate the Content consolidation section. The value you set there applies whenever content is consolidated into this resource.

When you configure consolidation for a specific project, the Allow context-based duplicates checkbox in the consolidation dialog inherits the value from the target translation memory. You can override it for that particular operation without changing the resource-level default.
Include/Remove comments
You can decide what do do with the comments available in the segments to be consolidated. By default, they are all included, which means you keep all the discussions and comments stored with that segment.
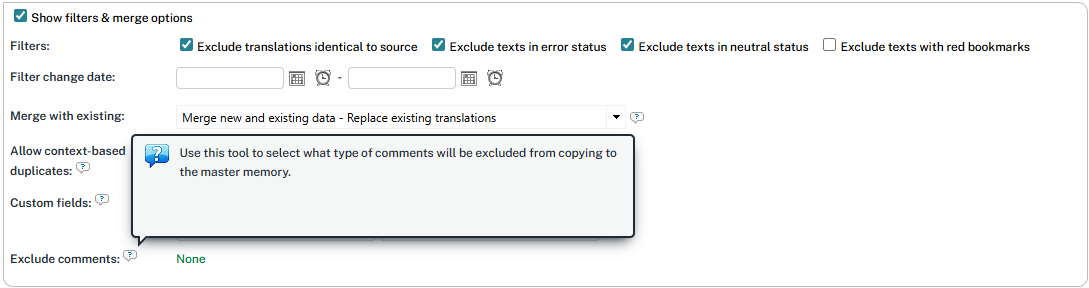
You will see other options when clicking on the right column (which shows "none" in the screenshot above):
-
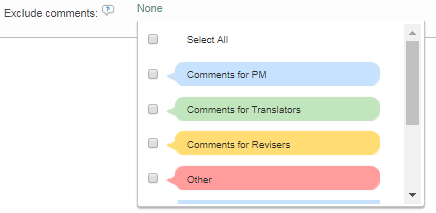
Exclude specific comment categories
-
Exclude multiple comment categories