
In real localization work, the same parser configuration often has to handle files that look slightly different from each other: column orders change between sheets, language column names use different conventions (English, EN, en-US, Anglais), and metadata columns sit in different positions. With Dynamic Detection of Column Names, you can configure a single parser that reads the column header row at processing time and maps each column to the right Wordbee field by name, no matter where it sits.
This applies to three parsers:
-
Multilingual Excel parser
-
Multilingual CSV parser
-
Monolingual by column Excel parser
When to use Dynamic Detection
Dynamic detection solves the cases where a fixed column layout cannot describe your files:
-
Columns shift between sheets. Sheet 1 has English in column A and French in column C; Sheet 2 has English in B and French in F. Both sheets share the same header row that names the languages.
-
Files share a layout but use different column names. One file labels the English column English, another en-US, another EN. You want one parser that accepts all of them.
-
Some files include extra metadata columns and others don't. A column for Context or a custom field is sometimes present, sometimes missing. You want the parser to skip missing optional columns without failing.
For files that always have the same fixed layout, the standard column configuration is simpler and sufficient: dynamic detection is for files where the layout varies.
How Dynamic Detection works
Dynamic detection runs once per sheet when a file is marked for online translation:
-
The parser reads the header row you configured (a single row number, applied to every sheet).
-
For each Wordbee field you mapped (a language column, a custom field, a context column), it tests each header cell against the regular expression you defined for that field.
-
The first column whose header matches the regex becomes the column for that field, for that sheet.
-
If a field's regex matches no header cell:
-
With Skip if not found enabled, the field is silently dropped for that sheet. The column does not appear in the Editor.
-
With Skip if not found disabled, the parser fails and reports which column was missing. You then fix either the file or the regex.
-
After translation, the reconstruction step writes each translation back to the column position where the header was originally found, sheet by sheet. So if English was in column A on Sheet 1 and column F on Sheet 2, the translations return to those exact positions.
Setting up Dynamic Detection
Follow these steps to configure dynamic column name detection:
-
Open Settings > Document Formats and open the configuration of one of the supported parsers: Multilingual Excel, Multilingual CSV, or Monolingual by column Excel.
-
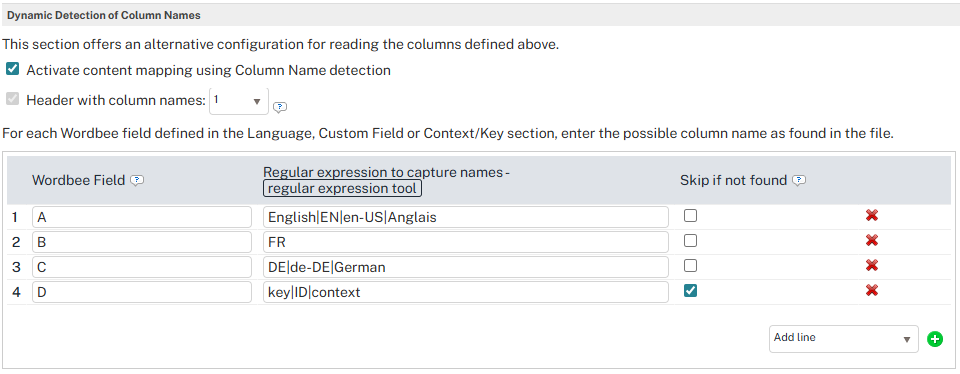
Configure the languages, custom fields, and any context or key columns the parser needs. Use any free column letter (A, B, C...) as a placeholder. The exact letter does not matter when dynamic detection is enabled, because the position is decided at processing time from the header row, but each placeholder must be unique within the configuration.
-
Scroll to the Dynamic Detection of Column Names section, just above the Rows section.
-
Enable Activate content mapping using Column Name detection.
-
In Header row, enter the row number that contains the column names in your files. The parser uses the same row number for every sheet.
-
In the mapping table, add one row per Wordbee field you want to detect:
-
Wordbee Field: the column letter you used in the parser sections above (for example, A for English).
-
Regular expression to capture names: a regex that matches any column header you want to treat as this field. Use the pipe
|to list alternative names (for example,English|EN|en-US|Anglais). -
Skip if not found: enable to drop the field silently when no header matches; leave disabled to fail the parse if the column is missing.
-
-
Save the configuration.
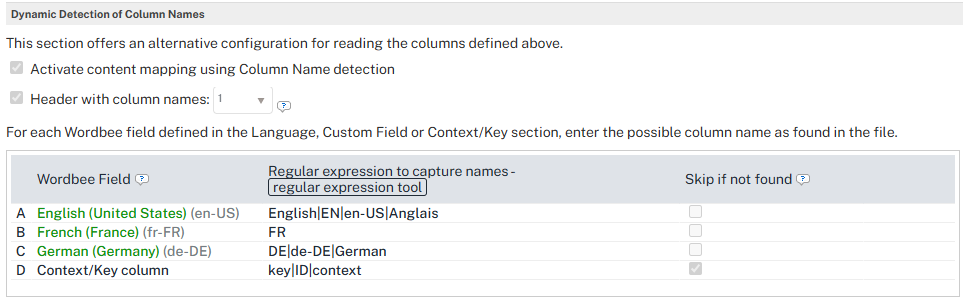
When you reopen the parser in View mode, the Wordbee Field column shows the field's friendly name (for example, English (United States)) instead of the letter, so the mapping is easier to verify.
Writing the regular expressions
The expression in Regular expression to capture names is a standard regex tested against the text of each header cell. A few practical patterns:
-
Match several names for one language:
English|EN|en-US|en_US|Anglais|en_text\(original\) -
Match a prefix:
^Source(\s|$)matches a header that starts with Source. -
Match case-insensitively: prefix with
(?i), for example(?i)englishmatches English, ENGLISH, and english. -
Escape special characters: parentheses and dots in the column name must be escaped, for example
English\s*\(USA\). -
Anchor the match to the full header:
^English$matches only the exact header English, not English Comments or Old English. Without anchors, a regex matches any cell that contains the pattern, which can produce false matches.
Within a single parser, each regex must be unique. If two rows use the same expression, the configuration shows a warning so you can resolve the conflict.
The first matching pattern wins. If two patterns can match the same header cell, the order of rows in the mapping table decides which Wordbee field claims that column. Put your more specific patterns first.
Handling missing columns
The Skip if not found flag controls what happens when none of the header cells match a row's regex on a given sheet:
|
Skip if not found |
Behavior when no header matches |
|---|---|
|
Enabled |
The Wordbee field is removed for that sheet. The column does not appear in the Editor. Other sheets are not affected. |
|
Disabled |
The parsing stops with an error that names the missing field. The file is not opened until you fix the file or the regex. |
Use Skip if not found for optional columns (a custom field that is sometimes present, a context column that is used only for code-style files). Leave it disabled for required columns where a missing column would mean a broken file.
If skipping leaves a sheet with too few language columns to translate (fewer than two languages in the multilingual parsers, or no language at all in the monolingual-by-column parser), the sheet itself is excluded from the project and the rest of the file continues to be processed normally.
Example Scenarios
|
Use Case |
How To |
|---|---|
|
One file has English in column A on Sheet 1 and English in column F on Sheet 2 |
Configure one row for English with regex |
|
Files arrive with the English column labelled as English, EN, en-US, or Anglais depending on the source |
Use the regex |
|
Some files have a Context column and others don't |
Map the Context column with Skip if not found enabled. Files without that column are processed normally; files with it use the column for context. |
|
You want the parser to fail loudly if a required language is missing |
Leave Skip if not found disabled for that language. The user gets an explicit error naming the missing column. |
|
The header row is on row 3 of every sheet (rows 1 and 2 are titles or formatting) |
Set Header row to 3. The parser skips rows 1 and 2 when looking for column names. |
|
You want to extract a key column named Key, ID, or StringId |
Map the Key column with regex |
|
The same column should match English exactly but not English Comments |
Use a strict regex like |
|
Different files reuse the same parser but pair different target languages |
Combine Dynamic Detection with Any Target Language in the column language setting, so both the column position and the language pair are resolved at processing time. |
Limits and validation
-
Header row: a single row number, applied to every sheet of the file. You cannot configure a different header row per sheet.
-
Field placeholder letters: only letters are accepted in the Wordbee Field column, and the same letter cannot be used twice in the same parser.
-
Unique regexes: each row in the mapping table must use a distinct regex. The configuration warns you when two rows share the same expression.
-
Regex timeout: each regex is given 500 milliseconds to evaluate against a header cell. Overly complex patterns that exceed this limit cause a parse error. Keep patterns simple.
-
Header row mismatch: if the configured header row does not exist in a sheet (for example, the sheet has only one row of data), and any mapped field has Skip if not found disabled, the parse fails.
Learn More
-
How to translate multilingual Excel files: the baseline workflow for multilingual Excel files without dynamic detection.
-
Translating Excel Files with Any Source or Target Language: another way to make one parser reusable across different language pairs.
-
Excel Configuration Options: full reference for every option in the Excel parser.
-
Microsoft Excel Files: overview of Excel file handling in Wordbee Translator.
-
Translating Excel files with existing translations: related workflow for files that already contain partial translations.