This article gives an overview of the default search and filter options available in the TM settings as accessed from a specific translation memory.
The default TM search settings will have an impact on the fuzzy match retrieval and consequently on word counting and invoicing.
In order to have the results refined per resource, you will need to play with the settings highlighted in each resource profile.
The global settings for your platform will define how your segments will be handled in the whole system.
If you do not know how to access the TM settings of a specific resource, see the previous article: Translation memory settings.
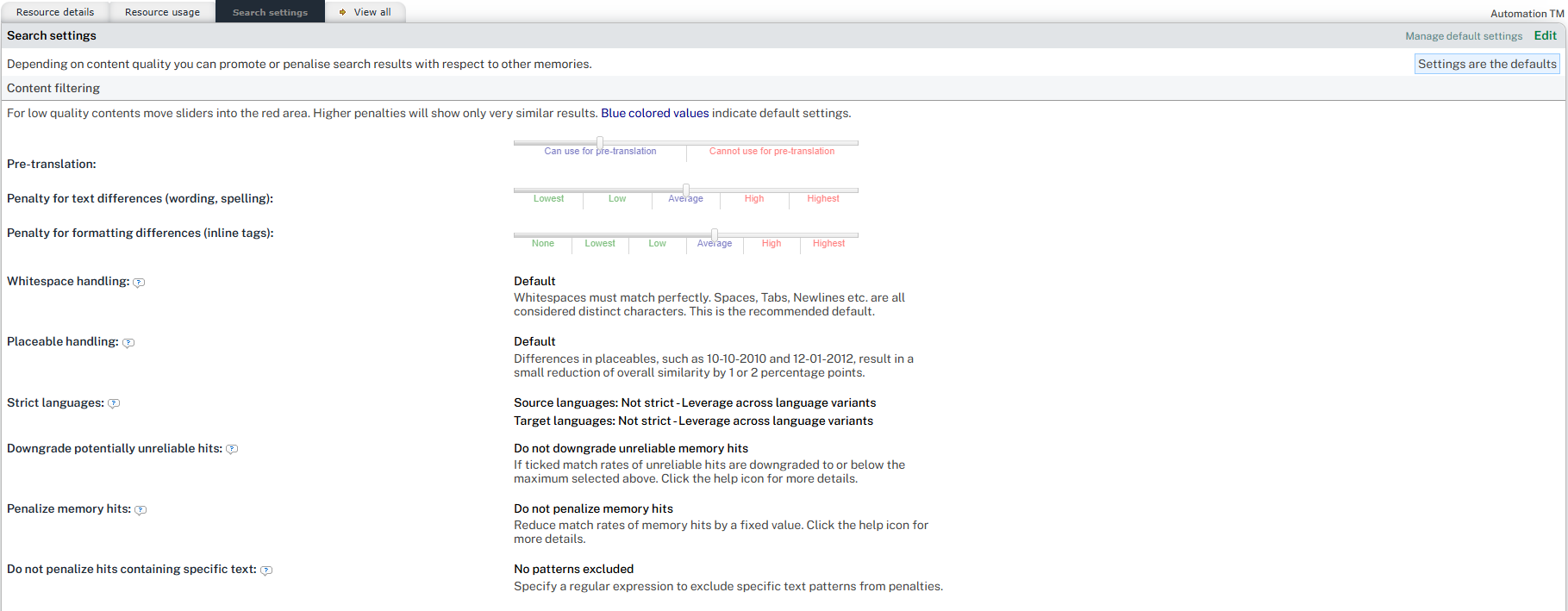
Default TM content filtering
After you have opened the Search settings of specific translation memory (or project memory, termbase), you can use the Content filtering options to define how this memory should behave with respect to other translation memories.
When you doubt the content quality of your resource, move the sliders of the pre-translation and penalty settings into the red area. Higher penalties will show only very similar results. Blue coloured values indicate default settings.
Expand the options below to learn more:
Pre-translation
Here you can define if Wordbee Translator can use the translation memory for pre-translation or not. In the screenshot, you can see the slider is set in the middle of the blue area: Can use for pre-translation. This means that the selected TM will be used for pre-translation and that the linguists will receive fuzzy matches during translation.
The pre-translation settings also have an impact on word counting.
Penalty for text differences (wording, spelling)
Here you can increase or decrease the penalty settings for text differences between the source segment and the match in the memory, for example, wording or spelling. The default settings are set to average.
Penalty for formatting differences (inline tags)
Here you can increase or decrease the penalty settings for formatting differences between the source text and the match in the memory, for example, inline tags. The default settings are set to average.
Whitespace handling
When the system compares a segment with a match in memory, it calculates the degree of similarity. By default, any differences in whitespaces such as a tabulator in one segment and a space in the other, or, one space vs. two spaces result in a similarity below 100% (identical match). You can adjust whether a less strict mode shall apply for whitespace differences.
You can apply one of the different settings:
Default settings - Whitespaces must match perfectly. Spaces, Tabs, Newlines etc. are all considered distinct characters. This is the recommended default.
Spaces, Tabs, Newlines are considered equivalent. For examples, 3 tabs equal to 3 spaces, but 2 tabs are different from 1 tab. The whitespace sequences must be of the same length.
Disregard any whitespace differences - This means that the system considers any single whitespace or sequences of whitespace as identical, for example, 3 tabs match 2 spaces at 100%.
Japanese/Chinese/Korean mode - If you translate from these languages, you could select this setting if you want the normal-width (Ansi) and full-width spaces to be considered identical.
Placeable handling
Placeables are dates, numeric values, decimals or similar elements. Differences in placeables between a memory hit and the searched text only slightly decrease the overall similarity. This setting specifies how much the similarity decreases.
You can apply one of the different settings:
Default setting - Differences in placeables, such as 10-10-2010 and 12-01-2012, result in a small reduction of overall similarity by 1 or 2 percentage points.
Zero penalty - The system assigns no penalty at all for placeable differences. This means that two texts containing distinct dates but are otherwise identical will be assigned 100% similarity.
Disabled - Placeable identification is disabled. For example, a difference could be that dates will give the same decrease in similarity as if the dates were two distinct words.
Strict languages
By default, a project can leverage resources if respective languages differ in the regional variant. For example, an English-US / English-GB / French-France project will leverage an English / French-Belgium resource. With this setting, you can enforce that leveraging is done only if languages match perfectly. The option concerns both source and target languages. This option is useful if you want to make a clear distinction between language variants and prevent any cross-leveraging.
Do not tick the setting “Strict - Do not leverage across language variants”, if you want the system to leverage your translation memory across all language variants.
If you tick the Strict language setting, it means that an 'English' resource is not leveraged when translating or counting an 'English US' document.
Downgrade potentially unreliable hits
An 'unreliable' match is a fuzzy pretranslation, an unedited machine translation or an unedited machine correction that was neither human post-edited nor explicitly flagged with a green status. Such hits are presented in the translation editor with the match rate having an orange background. The present option aims to downgrade the similarity rate of such hits below the original percentage to avoid confusion with reliable and approved matches.
If unticked, it means that the system will not downgrade unreliable memory hits.
If ticked, match rates of unreliable hits are downgraded to or below the maximum selected above.
Penalize memory hits
This option is useful if the quality of this resource is significantly below that of other resources. In that case, it may make sense to systematically reduce match rate percentages. For example, specifying a 5% penalty will display 95% instead of 100%, 80% instead of 85% and so on. A perfect match (110%) will be shown as 95%.
Tick the setting “Penalize all memory hits” toreduce the match rate percentage of a low-quality resource.
Do not penalize hits containing specific text:
Use this option to exclude specific text patterns from match penalties during similarity calculations. For example, you can enter a regex pattern such as %\d+ to ignore placeholders like %1, %2, etc. This ensures such patterns do not reduce the match rate percentage, improving pre-translation results. Make sure to use valid regex syntax.
Default translation filters
If you want to hide the default visibility of specific segments so you can guide users to better results available, you can customize the following filters:
Expand the options below to learn more:
Filter translations identical to source text
Here you can indicate if you want to filter translations identical to source text in two cases:
when linked from a project (i.e. the resource is attached to a project and such segments must appear as hits in the Translation Finder).
when editing the selected resource or project (i.e. such segments can be used during pretranslation or word counting processes). This setting is also dependent on the word-counting settings of the project.
Filter translations marked as erroneuous
Just as with the filter for 'Translations identical to source', here you can indicate if you want to filter translations marked as erroneous in two cases:
when linked from a project (i.e. the resource is attached to a project and such segments must appear as hits in the Translation Finder). Note this setting is also dependent on the Translation Finder settings the user has.
when editing the selected resource or project (i.e. such segments can be used during pretranslation or word counting processes).
Options like "Show translations identical to source" or "Show translations marked as erroneous (red status)" are available for all resource types: TMs, TBs, and Project Memory.
Default content consolidation
When content is moved into this resource (for example, during project memory consolidation), the data is processed according to the settings in the Content consolidation section.
Setting
Description
Filters
Select which segments to exclude: translations identical to source, texts in error status, texts in neutral status, and texts with red bookmarks.
Merge Languages
When checked, creates a locale in the target resource if it does not already exist.
Allow context-based duplicates
When enabled, segments with identical source and target text but different context (preceding or following segments) are stored as separate entries. This allows them to be correctly leveraged as 110% context matches.
Merge with existing
Choose how incoming segments are merged with existing entries.
Exclude comments
Choose whether to include or exclude segment comments, optionally filtering by category.
These defaults are inherited by the consolidation settings when consolidating into this resource. You can override them per consolidation from the project's Resources tab.