
This article shows you how to view and edit the default word count profile, and it gives an overview of the word count settings you can configure.
How-to view and edit the default word count profile
In the customization section of Word Counting, you can:
-
View and edit the details of the default word count profile.
-
Add new word count profiles for specific projects or suppliers.
When you edit or create a new word count profile, you need to take into consideration the pricelists you set up for each supplier and the discounts you applied for different match intervals.
When you access the settings page for the first time, you will find the default word count configuration. You can view or edit the default settings via the options available in the Select drop-down menu.
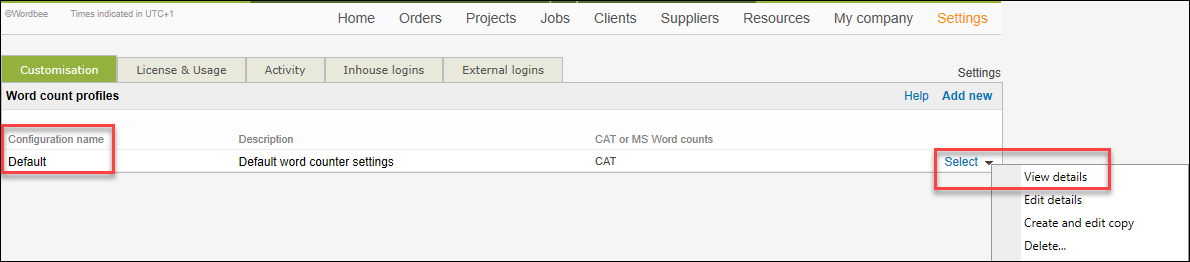
Step 1. Go to Select drop-down menu and use:
-
Select > View details if you want to view the default settings.
-
Select > Edit details if you want to change the settings.
-
Create and edit copy if you want to keep the default settings as they are.
-
Delete to remove the current default word count profile.
Step 2. In the editing mode you can view and adjust the following word count settings:
-
Fuzzy match intervals
-
Pre-translation options
-
Repetitions within project
-
Search parameters
-
Advanced word count settings
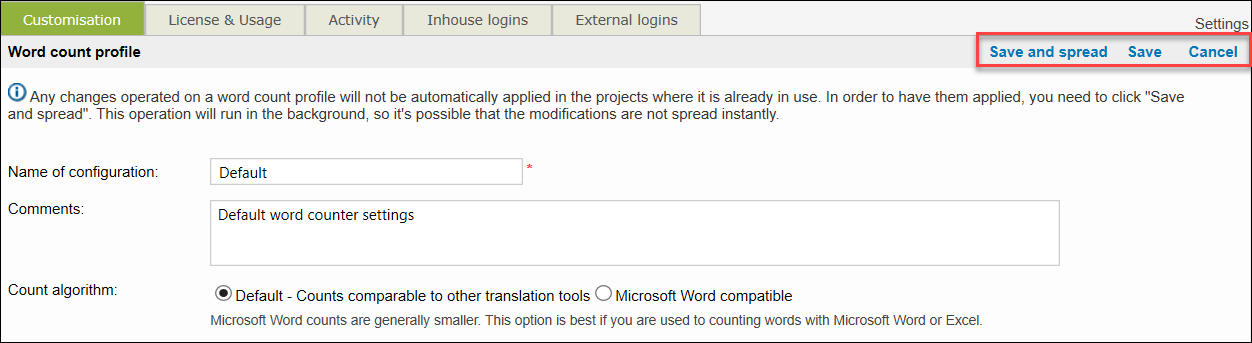
Step 3. When you finish adjusting the default word count profile,
-
Use Save if you want to save the changes you have made. Note that this option does not automatically apply the changes to a running project!
-
Use Save and spread if you want to apply the changes to projects where the default word count settings are already in use! This means that the modified settings will be applied to new documents marked for online translation in the running project.
-
Use Cancel if you want to cancel the changes you have made to the default settings.
Remember!
If you have updated the settings of a word count profile, these will apply to any new projects in the system. If the profile is beeing used in a running project, the changes will not be spread automatically! You have two options:
-
In Translation Settings, use Save and spread when updating the settings of a word count profile. This action will spread the changes to every ongoing project in which the word count profile has been assigned.
-
Go to the respective project, edit the project settings and select again the word count profile. This way new files marked for online translation within that project(s) will have the new settings applied.
The word count settings explained
Below you can view a description of all the settings you can configure for counting words, characters, segments, fuzzy matches and pre-translations. By default, Wordbee applies a counting algorithm that is compatible with other translation tools. Expand each option to learn more.
Fuzzy match intervals
Fuzzy match intervals
|
|
Description and additional explanations |
|---|---|---|
|
|
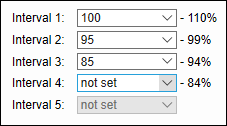
When you access the settings for the first time, you will see the following fuzzy match intervals set by default: |
The system will show the number of source words that were found in a translation memory with a certain degree of similarity. The different percentages or intervals indicate the amount of editing required. For example, matches between 85% and 110% are considered high fuzzy matches as little editing is required. Therefore, translators could apply various discounts on their full rate per word. Matches lower than 75% require more editing effort and even complete rewriting. In this case, no discounts apply. The match values need to correspond to the discounts on the fuzzy matches you negotiated with your suppliers. To check the pricelists, go to the Suppliers dashboard> select the supplier you would like to use and then open the Prices tab. 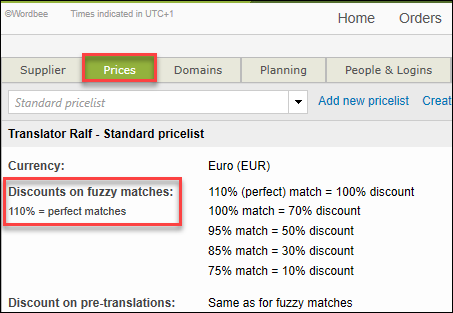
|
|
|
You can adjust the default configuration to match the discounts on the fuzzy matches you negotiated with each of your suppliers. Here is an example:
|
Note that Wordbee allows you to define discounts on both fuzzy matches and pre-translation matches. In the above example, the same discounts have been applied for both match categories. The percentages applied to the fuzzy matches in the pricelist is not the discount itself! Assuming that your full rate per word is 0.20 EUR and have negotiated a 50% discount with your supplier for the editing of 84%-99% fuzzy matches, this means that a weighted factor 0.50 is applied to your full rate per work and that you charge only 0.10 EUR for the editing of one fuzzy match in that category. |
|
|
100% - 110% matches |
110% stands for perfect or in-context matches: not only the source segment you are translating is similar to the one stored in the TM but also the context before and after the segment. In principle, perfect matches do not require any editing or review by linguists. 100% matches are exact matches: the active segment in the Editor is exactly the same as the one stored in the TM. In contrast with the perfect matches, 100% matches might need slight review. If you run a word count analysis on the same document in another translation tool, perfect matches might be recognized only as 100% matches because each tool stores different context information in the TM. |
|
|
95% - 99% fuzzy matches |
There are slight differences between the source segment you are currently translating and the one stored in the TM, such as capitalization, number, formatting, spacing. |
|
|
85% - 94% fuzzy matches |
The difference might consist of one full word between the source segment you are translating and the one stored in the TM. |
|
|
75% - 84% fuzzy matches |
There are more differences in words and formatting. |
|
|
50% - 74% fuzzy matches |
Matches below 75% require more editing or translation from scratch. |
Pre-translation settings
Pre-translation options
|
|
Description |
|---|---|---|
|
|
Pre-translation from memories |
If you select this option, the system will pre-translate segments from all project's resources, namely the project memory, translation memories or terminology databases. The threshold specifies whether exact or fuzzy matches are used to pre-translate the segments. It is recommended to set the threshold to 100%. |
|
|
Pre-translation from project memory |
If you select this option, the system will pre-translate segments only using the project memory. Should there be other translation memories attached to the project, the matches from the project memory will be proposed first. If this option is not selected, the project memory will be used to pre-translate repetitions only. |
|
|
Pre-translation by machine translation (MT) |
If you select this option, the system will pre-translate the source document (s) with the help of the Machine Translation when there are no matches coming from the Translation Memories. To enable one of the MT systems integrated into Wordbee (Google, Microsoft...), go to Settings > Machine Translation. See documentation. |
|
|
Count already translated segments as pre-translations |
If you select this option, a word count considers already translated segments as pre-translated (e.g. if a document is partially translated and a word count is re-run). This also applies to initial counting of multi-lingual Excel sheets, POT or XLIFF files which often already contain translations. Translations in red status (e.g. containing errors) are always disregarded. Segments without a translation are considered pre-translated if the segment status is green. |
|
|
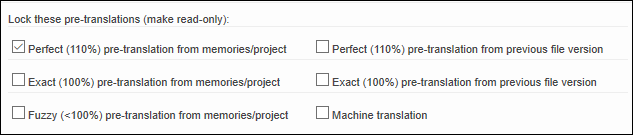
Lock pre-translations (make read-only) |
This option allows you to specify if pre-translations are automatically made read-only in the translation editor - indicated by the 'locked' icon. Usually, project managers lock the perfect matches as they do not require any editing work. If the segments are locked, the linguists are not able to modify them. Only authorised users (internal managers and team leaders by default) can unlock such translations for subsequent editing. You can configure the 'Can lock/unlock segments' access right is in the user profiles |
|
|
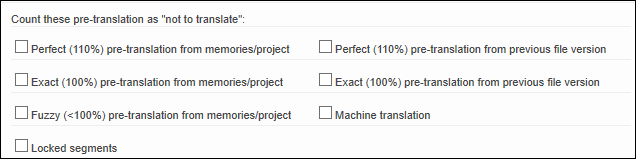
Count pre-translations as “not to translate” (do not cost) |
Use this option to count all or specific pre-translations as "not to translate". Any such counts are ignored by cost calculation. In addition, you might want to make these texts "read only" in the editor with the option above. |
|
|
Substitute dates and numbers |
If a very similar memory hit is used for pre-translation, dates and numbers are replaced with the corresponding dates and numbers from the source text (where these do differ). Such hits are not considered 100% identical and you will need to set the pre-translation threshold to below 100% if you want the system to pick them up for pre-translation. |
|
|
Fix markup during pre-translation |
If set, the formatting contained in a memory hit used for pre-translation is automatically adjusted: Inline tags (markup) are added, renamed or removed so as to match the translated text's formatting. Recommended setting. |
Repetitions within project
Repetitions within project
|
Description |
|---|---|
|
Enable repetition counting |
If you enable this option, the system will identify the repetitions within a project's documents and counts these as "fuzzy matches or repetitions". Repetitions are identical or similar segments that occur again and again within one document or across all documents in the project. Please note that the system will first try to pre-translate segments (if option is activated) and only then looks for repetitions or fuzzy matches in memories. |
|
Identical or similar repetitions
|
The system either counts identical repetitions only (100% to 110%) or extends the search to similar matches (within the fuzzy intervals indicated above). If you use this option, the system will count only the identical repetitions.
|
|
Translated or untranslated repetitions
|
When counting a document, the system counts translated and untranslated repetitions not only within the document itself but also across all documents in the project. If you use this option, the system will count only those repetitions that have been translated.
|
Search parameters
Search parameters
|
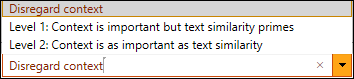
Promote hits with matching context: |
With this setting you can give additional boost to hits that have the same context as the segment being searched. The context of a segment typically contains formatting information such as "Heading 1", "Hyperlink" etc. or, when localizing software, string IDs or keys. This setting is specially useful for software localization projects! |
|---|
Related pages